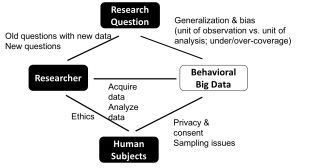
Next Tuesday I'll give a seminar talk on "A Tree-based Approach for Addressing Self-Selection in Impact Studies with Big Data" at The Hong Kong University of Science & Technology, in the department of Information Systems, Business Statistics, and Operations Management (lovely combination!). In the talk, I'll describe the cool tree-based method we developed for addressing self-selection as an alternative to propensity score matching (based our 2016 MISQ paper with Inbal Yahav and Deepa Mani).
For more details (where, when) see the poster.
For a very light non-technical description, see this 5-min video.
Abstract:
A major challenge in deriving insights from impact studies is differences between the treatment groups due to self‐selection or other factors unrelated to the intervention. We introduce a tree‐based approach adjusting for observable self‐selection bias in intervention studies in management research. In contrast to traditional propensity score matching methods, including those using classification trees as a subcomponent, our tree‐based approach provides a standalone, automated, data‐driven methodology that allows for (1) the examination of nascent interventions whose selection is difficult and costly to theoretically
specify a priori, (2) detection of heterogeneous intervention effects for different pre‐intervention profiles, (3) identification of pre‐intervention variables that correlate with the self‐selected intervention, and (4) visual presentation of intervention effects that is easy to discern and understand. As such, the tree‐based approach is a useful tool for analyzing observational impact studies as well as for post‐analysis of experimental data. The tree‐based approach is particularly advantageous in the analyses of big data. I'll illustrate the method and the insights it yields in the context of two impact studies with different study designs: reanalysis of a field experiment and observational data on the effect of training on earnings in the US; and analysis of a quasi‐experiment examining the impact of an e‐governance service in India.